Disaggregated Inference
The Architectural Revolution in AI Model Serving
Key Innovation
By separating the compute-intensive prefill phase from the memory-intensive decode phase, disaggregated inference achieves 15-40% infrastructure cost reduction while dramatically improving performance and scalability.
Resource Utilization Patterns
Introduction
Definition and Core Concept
Disaggregated Inference represents a fundamental reimagining of how computational resources are allocated during Large Language Model (LLM) inference. Unlike traditional monolithic architectures where all inference tasks are co-located on the same hardware, this approach separates a model's distinct inference phases onto dedicated, specialized resources.
The motivation for this architectural shift stems from the inherent inefficiencies and resource contention that arise when the two primary phases of LLM inference—prefill (context processing) and decode (token generation)—are forced to share the same hardware. These phases exhibit vastly different resource utilization patterns, creating a fundamental tension in traditional systems.
Addressing the Prefill-Decode Bottleneck
Prefill Phase
- • 90-95% GPU utilization
- • Compute-bound operations
- • Parallel matrix multiplications
- • Processes entire input simultaneously
Decode Phase
- • 20-40% GPU utilization
- • Memory-bandwidth-bound
- • Sequential token generation
- • KV cache intensive operations
When these phases are co-located, they create a "prefill-decode interference" problem. A long, compute-intensive prefill operation can starve the decode phase of memory bandwidth, while a batch of decode operations can delay the start of new prefill tasks. This architectural conflict results in poor overall performance, higher costs, and increased latency for all users.
Terminology and Nuances
Disaggregated Inference
The overarching architectural principle of separating distinct computational phases onto specialized resources.
Disaggregated Prefill
Specific focus on separating the prefill phase, highlighting the operational change in request routing and KV cache management.
Disaggregated Serving
The complete end-to-end system including routing logic, load balancing, and autoscaling policies for production deployment.
Technical Implementation: The Prefill-Decode Split
The Two Phases of LLM Inference
Prefill Phase
The initial stage where the model processes the entire input prompt simultaneously, building the Key-Value (KV) cache that represents the model's understanding of the context.
Time-to-First-Token (TTFT)
Decode Phase
The iterative, sequential process where the model generates output tokens one by one, using the KV cache populated during prefill to maintain context.
Inter-Token Latency (ITL/TPOT)
Resource Requirements and Bottlenecks
Compute-Bound Operations
The prefill phase is characterized by large-scale matrix multiplications and parallel operations that saturate GPU processing cores. Performance is limited by FLOPS, making high-throughput GPUs ideal for this workload.
Memory Bandwidth-Bound Operations
The decode phase is constrained by memory bandwidth, requiring rapid access to model parameters and the growing KV cache. GPU utilization typically ranges from 20-40% as cores wait for data.
Architectural Comparison
Aggregated Inference
Disaggregated Inference
Key Mechanisms and Components
KV Cache and Its Role
The Key-Value (KV) cache is the central data structure that enables efficient autoregressive generation. During prefill, the model computes and stores attention "keys" and "values" for each token, creating a compressed representation of the input context that the decode phase can efficiently access.
KV Cache Transfer Optimization
The transfer of the KV cache from prefill to decode clusters must be extremely efficient to avoid becoming a new bottleneck. Advanced frameworks like FlowKV have reduced transfer latency by 96-98% through techniques like memory reshaping and segment-based allocation.
NVLink, InfiniBand for direct GPU-to-GPU transfers
Overlapping transfer with computation to minimize latency
Scheduling and Load Balancing
Sophisticated orchestration systems are required to manage the flow of requests between prefill and decode clusters. Modern schedulers implement KV cache-aware routing, directing requests to decode servers that already have relevant context cached in memory.
- • Reduced latency through cache reuse
- • Dynamic scaling based on workload patterns
- • Optimized resource utilization across clusters
Benefits and Performance Improvements
Enhanced Performance Metrics
Reduced TTFT
Faster initial response through dedicated compute-optimized prefill clusters
Improved ITL
Smoother token generation with memory-optimized decode clusters
Higher Throughput
Increased system capacity through independent scaling
Performance Impact Analysis
Time-to-First-Token (TTFT) Optimization
By isolating the prefill workload on compute-optimized GPUs, the system ensures that prompt processing is not delayed by concurrent decode operations. This leads to dramatically lower TTFT, especially for long and complex prompts.
Inter-Token Latency (ITL) Improvement
The decode cluster, equipped with high-bandwidth memory, can access the KV cache much more efficiently when not competing with prefill operations. This results in lower and more consistent ITL.
Throughput and Latency Variance
Independent scaling of clusters allows optimal batching and higher overall utilization. The separation of phases dramatically reduces latency variance, providing more consistent and predictable performance.
Improved Resource Utilization and Cost Efficiency
Independent Scaling
The ability to scale prefill and decode clusters independently prevents the over-provisioning common in traditional systems. Resources can be allocated precisely where needed.
Cost Optimization
Infrastructure costs can be reduced by 15-40% through better resource allocation and eliminating the need to over-provision high-end GPUs for mixed workloads.
Heterogeneous Hardware Support
The disaggregated architecture naturally supports diverse hardware configurations. Organizations can build resilient, cost-efficient infrastructure using the best hardware for each specific task, avoiding vendor lock-in and optimizing price-performance ratios.
Prefill Cluster
- • High-FLOPS GPUs
- • Compute-optimized instances
- • Latest generation accelerators
Decode Cluster
- • High-memory-bandwidth GPUs
- • Cost-effective instances
- • Memory-optimized accelerators
Challenges and Design Considerations
System-Level Complexity
Distributed Architecture Management
Moving from a single-server model to a distributed system introduces classic challenges of distributed computing. The system must manage multiple separate clusters with their own lifecycles, requiring robust service discovery, health monitoring, and fault tolerance mechanisms.
- • Sophisticated orchestration layer for request routing
- • Graceful handling of node failures and rebalancing
- • Distributed state management expertise
Dynamic Rate Matching
The system must balance throughput between prefill and decode clusters. If prefill is too fast, it can overwhelm decode with KV cache transfers. If decode is too fast, resources will be underutilized waiting for prefill tasks.
Performance Overheads
Network Latency
KV cache transfer between clusters introduces network latency that can offset performance gains. For large models and long contexts, transfer times can be significant.
- • High-bandwidth, low-latency networking (InfiniBand)
- • KV cache compression and optimization
- • Asynchronous transfer techniques
Coordination Overhead
Distributed system coordination adds communication latency for scheduling decisions and state management.
- • Efficient communication protocols
- • State caching to reduce round-trips
- • Localized decision-making
Pragmatic Deployment Trade-offs
Throughput vs Interactivity
There's a fundamental trade-off between total throughput and individual user responsiveness. Disaggregated inference provides more tuning levers but doesn't eliminate this trade-off.
Workload Dependency
Benefits are most pronounced for diverse traffic patterns and larger models. For stable, predictable workloads or small models, complexity may not be justified.
Industry Adoption and Frameworks
Major Cloud Providers and Hardware Vendors

NVIDIA's Comprehensive Solution
TensorRT-LLM
High-performance inference engine with native support for disaggregated serving, enabling easy configuration of separate prefill and decode instances.
Dynamo Framework
State-of-the-art distributed inference framework written in Rust and Python, designed for hyperscale performance with dynamic GPU-to-request routing.

Google Cloud AI Hypercomputer
Integrated platform leveraging A3 Ultra GPU instances with vLLM and GKE orchestration for managed disaggregated inference deployment with separate node pools for prefill and decode stages.
- • NVIDIA H200 GPU acceleration
- • Google Kubernetes Engine for orchestration
- • Open-source deployment recipes
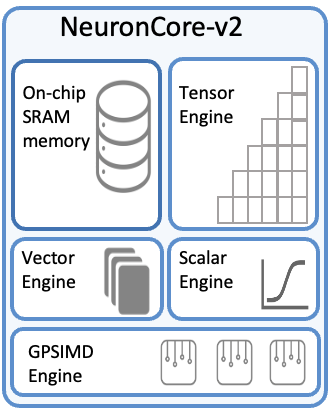
AWS Neuron SDK
Neuron SDK supports disaggregated inference on Trainium and Inferentia chips, providing tools for KV cache management and inter-stage communication orchestration.
- • Avoiding "prefill stall" scenarios
- • Improving inter-token latency predictability
- • Optimized performance on custom silicon
Open-Source Frameworks
vLLM
Highly popular library with innovative PagedAttention algorithm for efficient KV cache management, making it ideal for both prefill and decode phases in disaggregated systems.
Dynamic memory management for high throughput
SGLang
Flexible framework gaining popularity for disaggregated inference support, providing high-performance runtime and APIs for complex inference pipelines.
Extensible platform for multi-stage inference
Specialized Frameworks
Mooncake optimizes KV cache transfer with pull-based strategies, while DistServe provides explicit disaggregated architecture implementation.
Research-focused optimizations and implementations
Related Concepts and Future Directions
Distinction from Other Techniques
Model Parallelism
Splits large models across GPUs for memory efficiency. Disaggregated inference is orthogonal—it's about serving models by separating computational phases, not model parameters.
Mixture of Experts (MoE)
Activates subsets of model parameters for efficiency. Disaggregated inference can serve MoE models, but they operate at different levels: MoE disaggregates parameters, while disaggregated inference disaggregates computation.
Broader Infrastructure Context
Disaggregated inference is part of a larger trend toward composable infrastructure, where data center components are dynamically composed over high-speed networks.
Emerging Research and Optimizations
Efficient KV Cache Transfer
Advanced compression algorithms, predictive caching, and in-network processing to reduce transfer latency and bandwidth requirements.
Intelligent Scheduling
Sophisticated schedulers that make optimal placement decisions based on workload content and global KV cache state.
Hardware-Software Co-design
New hardware architectures and network protocols specifically optimized for disaggregated inference communication patterns.
Extended Disaggregation
Applying disaggregation principles to training, fine-tuning, and other AI pipeline stages for a fully composable AI stack.
The Future of AI Infrastructure
As Large Language Models continue to grow in complexity and capability, disaggregated inference represents more than an optimization—it's a fundamental architectural shift toward a more efficient, scalable, and cost-effective AI infrastructure.